Supervised Classification in GEE

Published on May 10, 2020 | Bikesh bade | 4630 Views
Supervised classification is the technique most frequently used for the quantitative chemical analysis of remote sensing image data. The supervised classification has supported the thought that a user can select sample pixels in a picture that are representative of specific classes so direct the image processing software to use these training sites as references for the classification of all other pixels within the image.
Supervised Classification in the Google Earth Engine
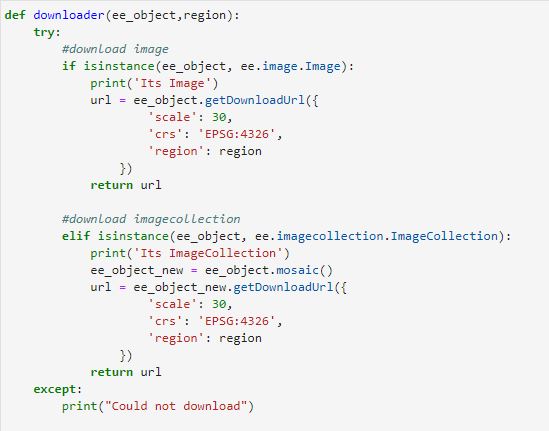
The Classifier package handles supervised classification by traditional ML algorithms running in Earth Engine.
The general workflow for classification is:
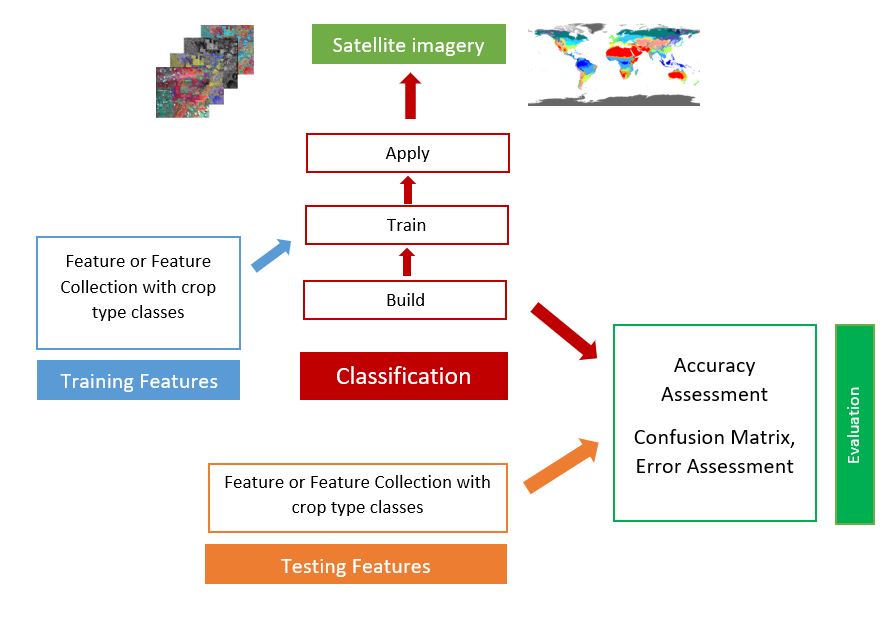
Google Earth Engine includes the following:
Classification And Regression Tree (CART)
A Classification And Regression Tree (CART), is a predictive model, which explains how an outcome variable's values can be predicted based on other values. A CART output is a decision tree where each fork is a split in a predictor variable and each end node contains a prediction for the outcome variable.
RandomForest
Random forest is a supervised learning algorithm. It can be used both for classification and regression. It is also the most flexible and easy to use the algorithm. A forest is comprised of trees. It is said that the more trees it has, the more robust a forest is. Random forests create decision trees on randomly selected data samples, get a prediction from each tree, and selects the best solution by means of voting. It also provides a pretty good indicator of the feature importance.
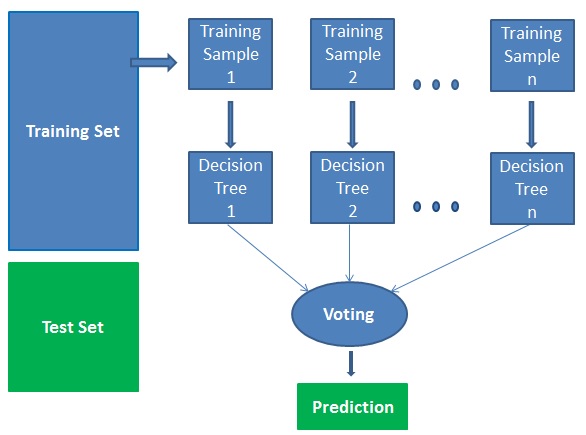
Example: Land cover mapping using Random forest
NaiveBayes
It is a classification technique based on Bayes’ Theorem with an assumption of independence among predictors. In simple terms, a Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature.
For example, a fruit may be considered to be an apple if it is red, round, and about 3 inches in diameter. Even if these features depend on each other or upon the existence of the other features, all of these properties independently contribute to the probability that this fruit is an apple and that is why it is known as ‘Naive’.Naive Bayes model is easy to build and particularly useful for very large data sets. Along with simplicity, Naive Bayes is known to outperform even highly sophisticated classification methods.
Support-Vector Machine (SVM)
A support vector machine (SVM) is a supervised machine learning model that uses classification algorithms for two-group classification problems. A Support Vector Machine (SVM) is a discriminative classifier formally defined by a separating hyperplane. In other words, given labeled training data (supervised learning), the algorithm outputs an optimal hyperplane which categorizes new examples. In two dimensional space, this hyperplane is a line dividing a plane into two parts wherein each class lay on either side.
All of the classifications have their own significance but general Random Forest is the latest and gives you a better result than others.